

Ever since OpenAI released ChatGPT to the world, people have been fascinated by its successes. And even more fascinated by its failures. I realize ChatGPT is no longer the hot new thing, but in this post I’m going to attempt a simple explanation what ChatGPT is really doing, in the hope that we will have a better understanding of what it can do. Or not do.
I’m not an AI expert, but I have been reading up on the technology, and I’m stealing some good stuff from the real experts.
Artificial Intelligence
Let’s start with the fact that ChatGPT is an example of artificial intelligence (AI). Don’t read too much into that phrase. Just because it’s called “intelligence” doesn’t mean it’s actually much like an intelligent human. AI is that ambitious, yes, but it’s not that good.
We use computers because they can solve certain kinds of problems faster and better than we can. For example, If someone gave you the job of adding up a list of numbers by hand, with pencil and paper, you might possibly be able to add 2000 numbers in an 8-hour workday, not including the time needed to check for mistakes.[1]I wasn’t able to find good historical information about human calculation speed. Meanwhile, my ordinary desktop computer can add a million numbers in less than a thousandth of a second, and it doesn’t make mistakes.
That kind of simple arithmetic falls into the class of problems that we humans are good at getting computers to solve for us. That’s possible, in part, because we understand how humans solve the problems — after all, we had to invent the algorithms for doing arithmetic in the first place.[2]In fact, algorithm probably originally referred to methods for doing basic arithmetic.
By comparison, the human ability to understand spoken language is still something of a mystery. We have a very incomplete understanding of how human brains do it, which has traditionally made it hard to program computers to do it. Computer scientists spent decades trying to get computers to understand spoken language, and for most of that time they would have said that understanding spoken language was impossible…except for the counter-example that every child learns to do it.
The same goes for problems such as extracting meaning from the written word, comprehending visual images, figuring out how to move objects around in the world, and playing complex games. These are problems that humans solve with relative ease, but we don’t know how we do it, and we don’t know how to program computers to solve these problems either.
Thus the phrase artificial intelligence is basically a broad term that computer scientists use for efforts to learn how to program computers to solve these kinds of problems. Calling some thing “AI” doesn’t mean it’s smart. It means that people are trying to get computers to solve the kinds of problems that human intelligence can solve.
Neural Networks
Artificial intelligence researchers have tried many different approaches to getting computers to think like humans, with varying degrees of success. In general, human-like intelligence is a much harder problem than many researchers thought in the 1960s and ’70s.
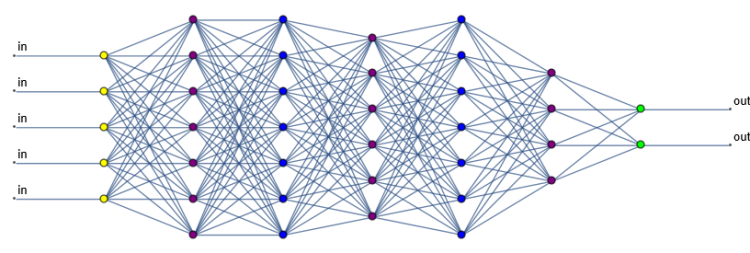
Lately, the most successful approach to solving artificial intelligence problems has involved machine learning (ML) using something called a neural network. When the idea was first conceived in the 1940s, it was originally thought AI neural networks could simulate how neurons in our brains work. It was conceptually simple: Neurons receive inputs from a handful of other neurons, and based on those inputs they produce an output, which goes on to feed the inputs of other neurons. So it made sense that if we could simulate the behaviors of neurons with which we think, we could simulate thinking.
In current AI research, as in parts of the brain, artificial neural networks are typically organized in a series of layers, and the most recent successes have involved deep learning networks with many layers. The first layer of simulated neurons receives the input data — words of English, pixels from an image, samples from the sound of someone speaking. The outputs from that layer are then spread across a bunch other neurons in the next layer. This process repeats, layer after layer, until the last layer generates the final output.

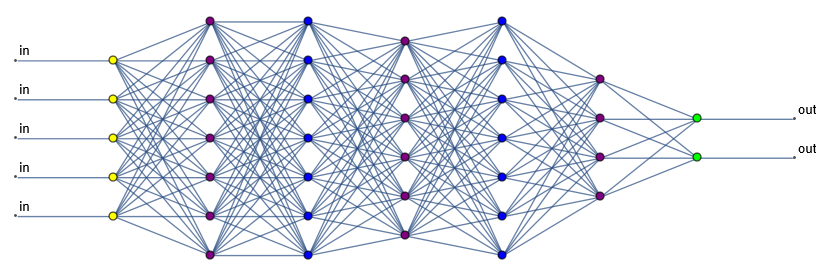
The simulated neurons themselves are simple: They take the inputs, do some simple arithmetic, and produce an output.[3]Since the invention of artificial neural networks, neuroscientists have learned a lot more about how the human brain works. It turns out that real neurons and their connections are a lot more complicated than these simulations. The exact relation between inputs and outputs of each neuron is controlled by a set of adjustable numerical parameters. For example, a neuron might take each of its inputs, multiply it by a weight parameter for that input, and add up the results of the weighed inputs to produce a value which is compared against a threshold parameter to determine the output. These parameters will be different for every single neuron in a network, and even the simplest useful networks have tens of thousands of parameters.
A task such as recognizing whether there’s a person in a visual image from a doorbell camera can require a neural network complicated enough to require between 5 and 50 million parameters. But the actual calculation is simple math, and we know how to make computers do simple math very quickly. (My computer multiplies 50 million numbers in about half a second, and it’s not optimized for parallel neural net computations.) In this way, neural networks turn a human-style intelligence problem into the kind of high-volume computation problem that computers can handle efficiently.
Training
You may be wondering where those billions of parameters come from. The answer is that the network has to be trained. This is why neural networks fall into the subcategory of artificial intelligence called machine learning.
Suppose we have a camera at our front windows, and we want to build a neural network to recognize if there’s a cat outside. Neural networking experts have learned through experimentation what kinds of neural networks are good for image recognition problems. The layers are specialized–some of them calculate relationships between nearby image pixels, others react to those relations, and so on. (Honestly, I don’t know much about this area.) Stack up a few of the right layers in the right order, set all of the parameters to their default starting values, and you’re ready to start training.
Now you need training data. In this case we need a whole bunch of pictures with cats in them. And since we also need to tell when a cat is not present in the image, we also need a whole bunch of pictures of the same locations without cats. We also need a source of truth: We need to know which pictures have cats in them and which don’t, meaning someone will have to look at each picture and record whether it includes a cat.
We then take the pictures and feed them to the neural network. For each picture, we use the values of the pixels as the input and run the neural network calculation — all 50 million parameterized calculations — until we get the output, which is an indication of whether or not the neural network believes the image includes a cat. The neural network’s result is checked against the known answer, and then the parameters of the connected neurons are adjusted one way or another depending on whether the neural network was right or wrong.[4]It’s complicated, and I don’t know the details of how these adjustments work. The result is that with each training image the neural network is a little more likely to get the right answer.
If the network is designed correctly, and the training set is large enough, and good enough, and fed through the network enough times, the network will become good at recognizing cats. Perhaps never as good as a human, but much better than anyone expected when researches first started experimented with neural networks.
Recognizer
At its heart, ChatGPT is what’s known as a large language model (LLM). Just as the neural network described above was trained to be a recognizer of cats, ChatGPT is a gigantic recognizer trained to recognize human-written text. OpenAI haven’t released the details of their most recent GPT-4 models, but the GPT-3 family of neural networks is known to have 175 billion model parameters organized into about 400 layers.
GPT-3 has been trained on pretty much every piece of human writing OpenAI could get their hands on — all of Wikipedia, millions of books, billions of web pages — probably half a trillion words. ChatGPT uses specialized network designs called transformers that can be trained in parallel and combined, which makes the training process feasible on such a large dataset.[5]It was the invention of modern transformers at Google a few years ago which ushered in the latest round of successful AI large language models. ChatGPT is trained to recognize all available human writing, so the source of truth is simply the presence of a writing sample in the massive training dataset.
In addition, ChatGPT has also been trained on a curated dataset arranged in a question-and-answer format, so that it learns to recognize the conversational format that we use when interacting with it.
Tokens
This section and the next one get a little bit technical, but I think it’s important to understand these details so we can see that ChatGPT is doing nothing very special when it answers our questions. Once the neural network has been trained, ChatGPT uses a simple, mechanistic, brute-force process to build answers to our prompts.
Chat GPT simplifies its model by breaking down all the training text into tokens. For example, the 8-word phrase
The Windypundit blog is written by Mark Draughn
is broken into the following 13 tokens:
The • Wind • yp • und • it • blog • is • written • by • Mark • Dra•ugh•n
As you can see, most common small words are tokens by themselves — “the”, “is”, even “blog” — but larger or more unusual words are broken into several tokens. This allows common words to be compactly represented by a single token, while larger or more unusual words can be represented by several tokens. In the worst case, there are single-letter tokens that allow any really unusual words to be spelled out. This allows common words to be represented compactly as single tokens while avoiding the need to have a token for every single word that ever appeared in the training set. ChatGPT can represent the hundreds of thousands of words of the English language, plus all the proper names of people and places, using only about 50,000 tokens.
Each token is stored as a simple number. For example, the sentence above is processed by the neural network as this array of numbers:
[464, 3086, 4464, 917, 270, 4130, 318, 3194, 416, 2940, 12458, 6724, 77]
The GPT-3 neural network behind basic ChatGPT can only analyze 4096 tokens at a time, which translates to about 3000 words. During training, larger documents have to be broken into chunks or simply truncated. OpenAI also has a GPT-3 model that can handle 16,384 tokens, and advanced GPT-4 models can handle 32,768 tokens, but these more capable models are up to 20 times more expensive to use.
Even with these kinds of tricks, training a large language model like ChatGPT is expensive. By some estimates, even with massive arrays of small GPU processors, the computer time for each training session of GPT-3 costs several million dollars.
Chat
Now we’ve finally reached the meat of the issue: What happens when you ask ChatGPT a question?
What is the capital of Illinois?
ChaGPT encodes that into an array of tokens (seven of them, including the question mark) like this:
[2061, 318, 262, 3139, 286, 9486, 30]
ChatGPT then takes that array of tokens and essentially tries to append each of the 50,000 or so possible tokens that could appear next in the sequence, using its neural network recognizer model to score how well each of the resulting token arrays resembles natural human text.
[2061, 318, 262, 3139, 286, 9486, 30, 1] -> score=0.0002350
[2061, 318, 262, 3139, 286, 9486, 30, 2] -> score=0.0000433
[2061, 318, 262, 3139, 286, 9486, 30, 3] -> score=0.0178293
[2061, 318, 262, 3139, 286, 9486, 30, 4] -> score=0.0039275
[2061, 318, 262, 3139, 286, 9486, 30, 5] -> score=0.0000042
and so on…
(I just made up these scores for illustration. ChatGPT doesn’t reveal this part of the process.)
ChatGPT then uses the scores to pick one of the sequences. It would seem to make sense to always pick the highest-scoring token sequence, but that turns out to produce answers that are repetitive and boring. Instead, ChatGPT chooses randomly from among several of the highest-scoring sequences. This element of randomness allows the text generation process to escape from its ruts and find better answers.
In this case, the sequence ChatGPT chooses is the array with token 383 at the end:
[2061, 318, 262, 3139, 286, 9486, 30, 383]
Since token 383 stands for the word “the”, the resulting text is now
What is the capital of Illinois? The
Finding that word required evaluation of the entire 175 billion parameter neural network.[6]I’ve skipped over the details of how this works, but ChatGPT has a way to calculate all 50,000 or so scores in a single pass, making it more efficient than it sounds. And out of all the possible first words for its response, ChatGPT thinks “the” is the word that makes the conversation come closest to being recognized as written human language.
Now ChatGPT repeats the process again, trying all fifty-thousand or so tokens again on the end of the new array and calculating new recognition scores:
[2061, 318, 262, 3139, 286, 9486, 30, 383, 1] -> score=0.0000528
[2061, 318, 262, 3139, 286, 9486, 30, 383, 2] -> score=0.0013677
[2061, 318, 262, 3139, 286, 9486, 30, 383, 3] -> score=0.0000033
and so on…
This time the winning array has token 3139 on the end, corresponding to the word “capital”, which brings our conversation to
What is the capital of Illinois? The capital
In five more iterations, ChatGPT completes the 7-token answer:
What is the capital of Illinois? The capital of Illinois is Springfield.
Actually, it’s a little more complicated than that because there’s a hidden token that tells ChatGPT to stop. There are also hidden tokens that separate the questions and answers. In any case, even simple questions like these can require many billions of calculations. This is why the better versions of ChatGPT are throttled and cost real money.
This got kind Of long…
So that’s what ChatGPT does. Unfortunately, this post is already kind of long, and I still haven’t reached the part where I talk about some of the implications. I’m going to split that off into a second post that I’ll try to publish in a few days.
Update: The second half is up.
Footnotes
| ↑1 | I wasn’t able to find good historical information about human calculation speed. |
|---|---|
| ↑2 | In fact, algorithm probably originally referred to methods for doing basic arithmetic. |
| ↑3 | Since the invention of artificial neural networks, neuroscientists have learned a lot more about how the human brain works. It turns out that real neurons and their connections are a lot more complicated than these simulations. |
| ↑4 | It’s complicated, and I don’t know the details of how these adjustments work. |
| ↑5 | It was the invention of modern transformers at Google a few years ago which ushered in the latest round of successful AI large language models. |
| ↑6 | I’ve skipped over the details of how this works, but ChatGPT has a way to calculate all 50,000 or so scores in a single pass, making it more efficient than it sounds. |
[…] my previous post on this subject, I gave a brief outline of how ChatGPT is based on a neural network that has been trained on a huge […]