So the other day, according to someone named Ryan Saavedra, newly elected congresswoman Alexandria Ocasio-Cortez said that algorithms are racist:
Socialist Rep. Alexandria Ocasio-Cortez (D-NY) claims that algorithms, which are driven by math, are racist pic.twitter.com/X2veVvAU1H
— Ryan Saavedra (@RealSaavedra) January 22, 2019
Socialist Rep. Alexandria Ocasio-Cortez (D-NY) claims that algorithms, which are driven by math, are racist
— Ryan Saavedra @RealSaavedra
Ocasio-Cortez says a lot of crazy things, but this is not as crazy as it sounds. Obviously, algorithms cannot be racist in the way that humans are racist — they don’t have feelings about people of different races — but there are applications of algorithms that can fairly be described as racially biased.
The word “algorithm” has a traditional meaning in computer science: It’s the rules a program must follow to manipulate data to solve a problem. These are usually very concrete, expressed in code (or pseudocode) in exacting detail. For example, here’s an algorithm I threw together in the C# programming language to solve the problem of finding all the prime numbers in a range from lo to hi:
private static List<int> GetPrimes(int lo, int hi)
{
var primes = new List<int> {2};
for (int i = 3; i <= hi; i+=2) {
var maxFactor = Math.Sqrt(i);
foreach (int factor in primes) {
if (factor > maxFactor) break;
if (i % factor == 0) {
goto not_prime;
}
}
primes.Add(i);
not_prime:;
}
return primes.Where(p => lo <= p && p <= hi).ToList();
}You can use this algorithm to find out that the range 100 to 200 contains the prime numbers 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151, 157, 163, 167, 173, 179, 181, 191, 193, 197, and 199. If you want to give it a test drive you can run it on .NET Fiddle. (The algorithm is not designed to be efficient for really big integer inputs, so it’s probably best not to set lo and hi greater than about 10 million or the algorithm might run too long.)
This is where Saavedra sort of has a point, because this is not a racist algorithm, and there’s no way it could be. But that’s not because it’s “driven by math.” This algorithm can’t be racist because racism is about people, and this algorithm is not about people.
Once you add people into the mix, it’s not hard to create a racist algorithm. For example, banks use algorithms to calculate a score indicating whether they should loan someone money for a home mortgage. It would be easy to modify the algorithm to, say, reduce an applicant’s score by 10% if they’re black.
You could probably make a pedantic argument that “racist” is the wrong word to describe this algorithm because the algorithm doesn’t feel hate toward black people, but we can safely say that it prejudges black people and puts them at a disadvantage. I think we can fairly call that racist.
In this day and age, no U.S. bank would do anything so blatantly discriminatory. But that doesn’t mean the algorithm couldn’t still function in a racist manner.
Consider the basic question the bank is trying to answer: If we loan the applicant our money, will they pay it back? (There’s more to loan analysis than that, but it’s certainly one of the key questions.) That’s a difficult question to answer for one very obvious reason: It’s about the future, and the future hasn’t happened yet. Whether someone will pay back a loan is essentially unknowable at the time you make the decision to lend them money. But there are a lot of clues.
For example, you can look at the borrower’s history of making payments on other loans (i.e. their credit history). Unlike their future payments, their history of past payments is available to us. And it makes sense that someone who has paid their debts in the past will continue to pay their debts in the future. Their past loan payment patterns predict their future loan payment patterns.
A person’s income is another good predictor of future debt payments, because a person’s capacity to make loan payments is constrained by their wealth and income. The source of their income could be important too, because some jobs are more at risk of extended unemployment than others, and it doesn’t matter how good their credit history is, or how much they earn on the job, if they could lose their job and not find another quickly.
Furthermore, since these are mortgage loans, there will be a lot of information about the property that secures the loan, such as the value of the house, the size of the house, how many bedrooms it has, construction details, and where it’s located. These could all turn out to be statistically significant predictors of future loan repayment.
To build an algorithm that takes these things into account, data scientists would begin by gathering a massive database of historic loan data, including all the information I’ve been describing plus information about how well the loan performed (was it paid back, were payments late, etc.). They would then try to build a mathematical model that predicts loan performance based on what was known about the loan at the time of the application.
The goal is to find a model that does a good job at predicting loan performance for loans in the database, and then apply it to new loans to try to predict how they will do. This is how we can make predictions about whether people will pay back loans in the unknowable future, using data that that we have right now in the present.
Statisticians have been doing things like this for years — fitting models to data and then using the models to make predictions. (In some sense, every expansion of scientific knowledge takes this form.) In recent years, this has expanded into into the fields of data science, predictive analytics, and machine learning, and there’s a whole world of software tools to make the job easier.
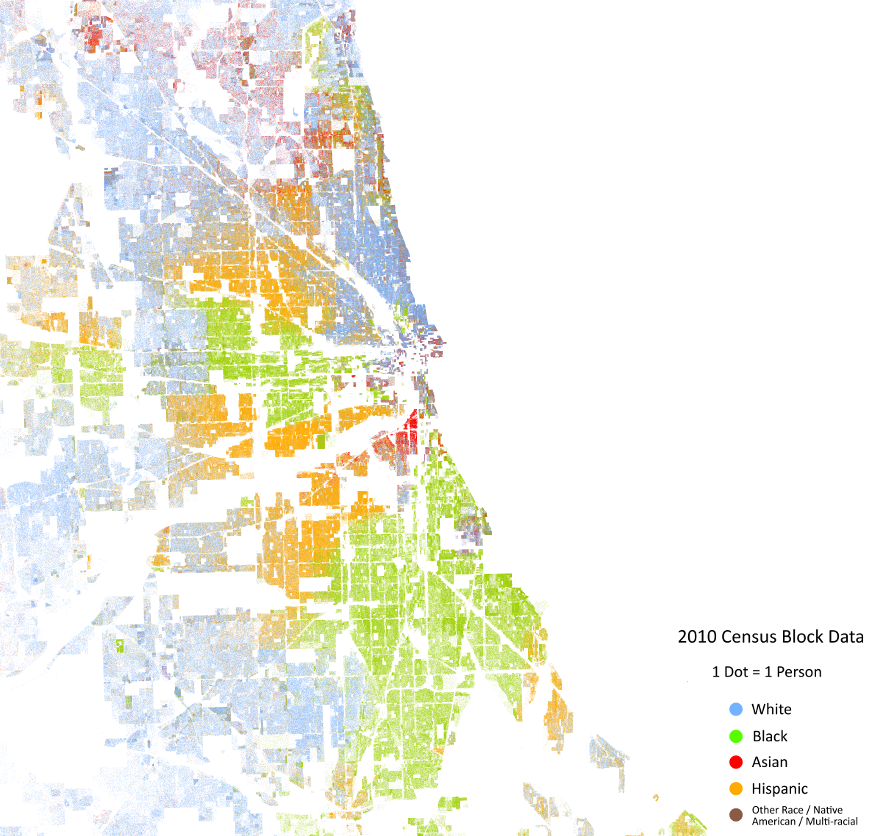
Getting back to our mortgage loan model, a few potential sources of racial bias have already begun to creep in. To start with, take a look at this map of where people of different races live in my hometown of Chicago:
(You can see a scrollable map like this for the whole United States at the Cooper Center demographics research group at Virginia University.)
The map shows that people of the same race tend to clump together. So if you know where a house is located, you have a pretty good idea of the race of the people living there. This might be a problem for our loan payment model if (1) it predicts that loans on homes in certain locations have higher default rates, and (2) those locations tend to be occupied by racial minorities.
In data science terms, the home’s location would then be serving as a proxy for the race of the homeowner. Even though we have deliberately chosen not to incorporate the borrower’s race in our loan prediction model, we’ve incorporated another variable that correlates to race, which has the same effect. We have, perhaps quite unintentionally, introduced race as a factor in our loan scoring.
Some of the other model variables may also be race proxies, such as the amount and source of income. Black households have, on average, lower incomes than white households, so by denying loans to people with low incomes, banks are disproportionately denying loans to black people. And certain jobs are heavily segregated. So if a loan applicant lists their employment as “veterinarian,” there’s a 95% chance they’re white. A loan approval process that favors veterinarians may also favor white people.
On the other hand, banks are in the loan business because they want to make money, so not making profitable loans because the borrowers are black would be a business mistake. In fact, most studies of loan default rates find that blacks and whites are equally likely to default on a home loan, which implies that banks are not holding blacks to a higher standard or giving out loans to less qualified white people.
That we can check the accuracy of the loan approval algorithm against real world results is very important, because it allows us to correct errors. That’s possible because the loan default rate is negative feedback, which means it can be used to push the algorithm back in the right direction. So if the default rate is too high for, say, mortgages on townhouses, the bank can tune the algorithm to be more strict about approving loans to buy townhouses.
Unfortunately, not all models are so self-correcting. For example, a law enforcement agency’s predictive policing algorithm might notice that crime is rising in a particular neighborhood and recommend that more police officers be assigned there. If the crimes monitored by the algorithm are violent ones like homicide and assault, the additional police may help reduce them.
But if the crimes being monitored include nuisance crimes such as vagrancy, public drinking, or panhandling (perhaps under a “broken windows” theory of policing), it’s likely that the majority of these crimes have been missed or ignored by the police, meaning the the reported rate is only a small fraction of the true rate. In that case, there are plenty of unreported crimes to discover, so if police departments put more effort into it, they will discover more crimes.
This creates a pernicious positive feedback loop. It becomes possible for a few racist cops to over-aggressively arrest a lot of people in predominantly black neighborhoods, producing an apparent increase in the crime rate for those neighborhoods. That could trigger the predictive policing algorithm to assign more officers into the area, where those officers will make even more arrests for even more nuisance crimes. That will drive up the reported crime rate again, which could cause the predictive policing algorithm to assign even more police, and so on. In this way, positive feedback can cause an algorithm to capture and amplify the racism of the people in the system.
These effects can go on to affect other algorithms. For example, an algorithm for a recidivism model — such as those used for sentencing and parole decisions — may take into account the likelihood that number of arrests a person has on their record, or even the number of people in that person’s neighborhood who are criminals, both of which could artificially inflated by runaway positive feedback in the predictive policing algorithm. Those arrests could also get plugged into analytics tools for evaluating job applications, leading to rejections of people with criminal records.
Speaking of job applications, it can be useful to score applicants by where they live, since people with longer commutes are more likely to quit sooner. That sounds like a neutral decision, unless the company is located in a predominantly white area, in which case the geographic scoring will have the effect of preferring white people.
These days, machine learning is all the rage. So if a company has a historic database of 100,000 job applications which lead to 10,000 people being hired, a data scientist might feed that database to a machine learning system in the hope that it will generate an algorithmic model that will mimic the hiring decisions of the company’s managers. If the algorithm can narrow down the applicant field by rejecting 80,000 applications before any human sees them, that will speed up the hiring process a lot. Of course, if the hiring managers were racially biased, the machine learning model could learn to mimic their bias.
This sort of thing happens a lot, and professional data scientist Cathy O’Neil wrote a pretty decent book called Weapons of Math Destruction about the ways which big data modeling can go wrong, including some of the ways models can capture and replicate racial bias. We can make philosophical arguments about whether this is really racist, but it’s not how we want our algorithms to work.
Nicely done. Reinforces my faith in logical thinking. Probably does the same for most of your readers. Unfortunately, it will do nothing for most of the world which does not seem to use or understand the concept of logic. I spent some time perusing a subreddit this morning and it was incomprehensible. Just had to tell someone about my close encounter with the abyss.